第5课-蒙特卡洛方法(通过例子介绍蒙特卡洛)知识点整理
第5课-蒙特卡洛方法(通过例子介绍蒙特卡洛)知识点整理
蒙特卡洛估计(Monte Carlo Estimation)核心思想
1. 问题引入:抛硬币期望估计(示例)
-
问题定义:抛一枚硬币,结果用随机变量 表示:
- 正面:
- 反面:
- 目标:估计 的期望
-
两种求解思路对比
| 方法类型 | 核心逻辑 | 计算过程 | 局限性 |
|---|---|---|---|
| Model-based(基于模型) | 已知随机变量的概率分布,直接用期望定义计算 | 若 ,则 | 实际中常未知环境分布(模型),无法直接应用 |
| Model-free(蒙特卡洛估计) | 无需已知分布,通过大量采样求均值近似期望 | 1) 做 次独立试验得样本 ();2) 计算 ;3) 令 | 小样本方差大,需要足够大 才能逼近真实期望 |
2. 蒙特卡洛估计的数学支撑:大数定理(Law of Large Numbers)
-
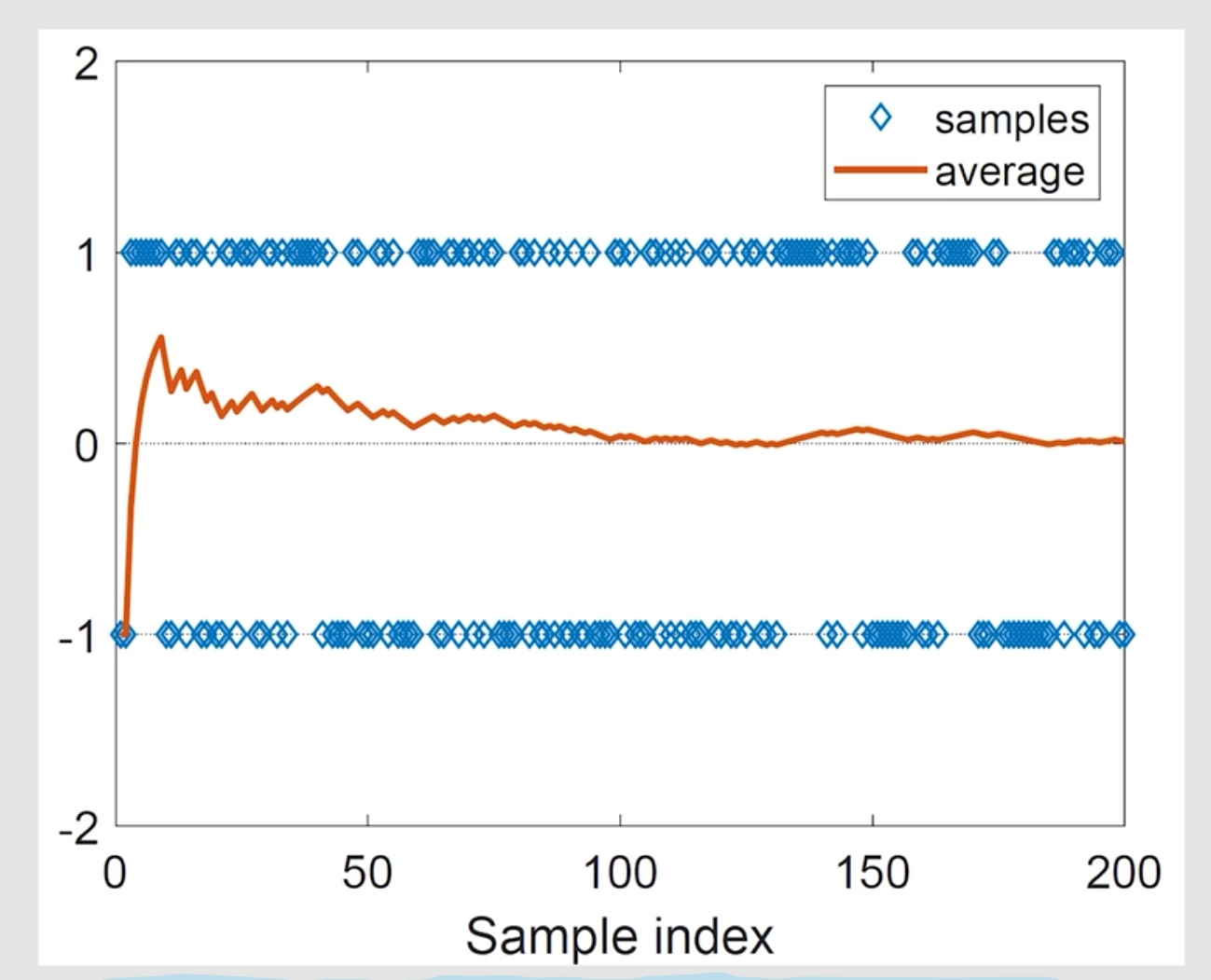
前提条件: 为独立同分布(i.i.d.)样本。
-
核心结论:
- 无偏性:
- 方差收敛: 因此 以概率 1 收敛到 。
-
可视化说明:
3. 蒙特卡洛估计在强化学习中的意义
- 价值函数本质:强化学习中的状态价值 与动作价值 均是“未来回报的期望”。
- 适配原因:当环境模型(转移概率与奖励分布)未知时,可通过采样完整 Episode 回报的平均来估计这些期望。
关键概念辨析与重要提示
- 广义蒙特卡洛方法:凡“通过随机采样并用统计量(如均值)近似目标量(如期望)”的思想都属蒙特卡洛范畴。
- MC Basic 算法定位:虽数据效率低、需完整 Episode,但其思想奠定“脱离模型仍能估计期望”的基础,是改进算法(如增量式、带控制)前置概念。
- 与后续方法对比:蒙特卡洛需完整轨迹;时序差分(TD)可在未终止前更新,二者共同构成无模型强化学习的两大核心思路。
第5课-蒙特卡洛方法(MC Basic算法)核心知识点整理
前置知识回顾
MC Basic算法是Policy Iteration(策略迭代)的Model-Free变形,需先掌握策略迭代的核心逻辑与动作价值函数的定义。
Policy Iteration(策略迭代)算法
策略迭代是Model-Based(依赖环境模型)的强化学习算法,每轮迭代包含两个核心步骤:
-
Policy Evaluation(策略评估)
已知当前策略,通过求解贝尔曼方程,计算该策略下所有状态的状态价值函数(即从状态出发,遵循的期望回报):
其中,是环境模型(状态转移概率+即时奖励分布),是折扣因子()。 -
Policy Improvement(策略改进)
基于评估得到的,通过最大化动作价值函数 更新策略,得到更优策略:
动作价值函数的两种计算方式
表示“从状态出发,执行动作后遵循策略”的期望回报,是策略改进的核心依据,其计算分为两类:
| 计算方式 | 依赖模型? | 公式表达 | 适用场景 |
|---|---|---|---|
| Model-Based | 是 | $q_{\pi}(s,a) = \sum_{s’,r} p(s’,r | s,a) \left[ r + \gamma v_{\pi}(s’) \right]$ |
| Model-Free | 否 | $q_{\pi}(s,a) = \mathbb{E}_{\pi}[G_t | S_t = s, A_t = a]$ |
其中,是折扣回报(Discounted Return),定义为:
是episode(回合)的终止步,是时刻的即时奖励。
Monte Carlo Mean Estimation(蒙特卡洛均值估计)
核心作用:在无环境模型时,通过采样多个独立样本的均值,估计随机变量的期望。
对应到强化学习:是的期望,因此可通过采样多个从出发的episode,计算每个episode的,再求均值作为的估计:
其中,是采样的episode数量,是第个episode的折扣回报。
MC Basic算法核心思想
MC Basic的本质是将Policy Iteration中“依赖模型的计算”替换为“基于蒙特卡洛采样的估计”,从而实现Model-Free(不依赖环境模型)的策略迭代。
核心逻辑:
- 无模型 → 无法用计算;
- 替代方案 → 用“采样数据(Experience)”估计(即蒙特卡洛均值估计);
- 最终目标 → 保持Policy Iteration的“评估-改进”框架,同时摆脱对环境模型的依赖。
MC Basic算法步骤与伪代码
算法整体流程
MC Basic的每轮迭代(第次)仍分为“策略评估”和“策略改进”两步,核心差异在策略评估的实现:
步骤1:Policy Evaluation(策略评估,Model-Free版)
对所有状态-动作对,执行以下操作:
- 从出发,遵循当前策略,生成个独立的episode(需足够大以保证估计精度);
- 对每个episode,计算从开始的折扣回报;
- 用样本均值估计:
步骤2:Policy Improvement(策略改进,与Policy Iteration一致)
对每个状态,选择使最大的动作作为新策略:
伪代码(Pseudocode)
1. 初始化:
- 选择任意初始策略π₀(如随机策略)
- 设定折扣因子γ、采样episode数量N
2. 迭代(k=0,1,2,... 直到策略收敛):
a. 策略评估(估计q_πₖ(s,a)):
对所有状态s ∈ S:
对所有动作a ∈ A(s):
生成N个从(s,a)出发、遵循πₖ的episode
计算每个episode的折扣回报G_t⁽¹⁾, G_t⁽²⁾, ..., G_t⁽ᴺ⁾
估计q_πₖ(s,a) = (1/N) * ΣG_t⁽ⁱ⁾(i从1到N)
b. 策略改进(更新为πₖ₊₁):
对所有状态s ∈ S:
πₖ₊₁(s) = argmaxₐ q_πₖ(s,a) (选择使q值最大的动作)
3. 输出最终收敛的策略π*MC Basic与Policy Iteration的关键对比
| 对比维度 | MC Basic(Model-Free) | Policy Iteration(Model-Based) |
|---|---|---|
| 策略评估方式 | 蒙特卡洛采样(样本均值估计q_π) | 求解贝尔曼方程(先求v_π,再转q_π) |
| 是否依赖环境模型 | 否(依赖采样数据/经验) | 是(依赖p(s’,r |
| 值函数估计对象 | 直接估计q_π(s,a) | 先估计v_π(s),再推导q_π(s,a) |
| 数据需求 | 大量episode采样数据 | 无需数据(需模型参数) |
| 计算效率 | 低(需遍历所有(s,a)并采样多episode) | 高(方程求解,无采样开销) |
MC Basic算法特性与注意事项
收敛性
- 核心结论:MC Basic的收敛性与Policy Iteration一致,当采样数量N→∞时,q_π的估计值收敛到真实值,最终策略会收敛到最优策略π*。
- 原因:蒙特卡洛均值估计是无偏估计,当样本量足够大时,估计值趋近于真实期望;策略改进步骤与Policy Iteration完全相同,保证策略单调递增。
效率与实用性
- 效率低:需遍历所有状态-动作对,且每个需采样多个episode,数据利用率极低,计算成本高。
- 实用性差:MC Basic是讲师为“剥离核心思想”自定义的算法(非通用标准算法),实际中不会直接使用,但它是后续高效MC算法(如MC Exploring Starts、MC ε-Greedy)的基础。
直接估计q_π的原因
MC Basic选择直接估计,而非先估计,核心原因是:
- 从推导需要环境模型(Model-Based),而MC Basic是Model-Free算法,无法获取模型参数,因此必须直接估计。
核心思想价值
MC Basic的最大意义是清晰揭示了“从Model-Based到Model-Free”的转化逻辑:
即“用‘采样数据的统计估计’替代‘模型参数的解析计算’”,这是所有蒙特卡洛类强化学习算法的核心思路。