值迭代算法核心基础
算法来源 :基于第3课的 贝尔曼最优公式 ,通过 “压缩映射定理(Contraction Mapping Theorem)” 可证明:按值迭代算法迭代即可收敛到最优策略与最优状态值(Optimal State Value)。
关键概念澄清 :迭代过程中的 v k v_k v k 向量/数值 ,仅用于逐步逼近最优值,这也是“值迭代”名称的由来。
值迭代算法核心步骤(含数学形式与实现逻辑)
值迭代算法分为 “策略更新 (Policy Update)” 和 “值更新 (Value Update)” 两步,可用“元素形式(编程实现)”来理解:
1. 两步核心流程
步骤 目标 数学逻辑(元素形式) 实现关键操作 策略更新 基于当前 v k v_k v k π k + 1 \pi_{k+1} π k + 1 对每个状态 s s s a a a q k ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ ) q_k(s,a) = r(s,a) + \gamma \sum_{s'} P(s'\mid s,a)\, v_k(s') q k ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ ) a ∗ a^* a ∗ 1. 遍历所有状态;2. 计算 q k ( s , a ) q_k(s,a) q k ( s , a ) 值更新 基于 π k + 1 \pi_{k+1} π k + 1 v k + 1 v_{k+1} v k + 1 v k + 1 ( s ) = max a q k ( s , a ) v_{k+1}(s) = \max_a q_k(s,a) v k + 1 ( s ) = max a q k ( s , a ) 复用 q k ( s , a ) q_k(s,a) q k ( s , a ) v k + 1 ( s ) v_{k+1}(s) v k + 1 ( s )
2. 算法终止条件
若 ∥ v k + 1 − v k ∥ < ϵ \lVert v_{k+1} - v_k \rVert < \epsilon ∥ v k + 1 − v k ∥ < ϵ ϵ = 10 − 3 \epsilon=10^{-3} ϵ = 1 0 − 3
值迭代算法伪代码(可执行框架)
初始化:任意设置初始值向量 v 0 v_0 v 0 ϵ \epsilon ϵ
循环(直到收敛):对每个状态 s s s
计算每个动作:q ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ ) q(s,a) = r(s,a) + \gamma \sum_{s'} P(s'\mid s,a)\, v_k(s') q ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ )
策略更新:取使 q ( s , a ) q(s,a) q ( s , a ) a ∗ a^* a ∗ π k + 1 ( s ) = a ∗ \pi_{k+1}(s)=a^* π k + 1 ( s ) = a ∗
值更新:v k + 1 ( s ) = max a q ( s , a ) v_{k+1}(s) = \max_a q(s,a) v k + 1 ( s ) = max a q ( s , a )
收敛判定:若所有状态 ∣ v k + 1 ( s ) − v k ( s ) ∣ < ϵ |v_{k+1}(s) - v_k(s)| < \epsilon ∣ v k + 1 ( s ) − v k ( s ) ∣ < ϵ v k ← v k + 1 v_k \leftarrow v_{k+1} v k ← v k + 1
输出:最优策略 π ∗ = π k + 1 \pi^* = \pi_{k+1} π ∗ = π k + 1 v ∗ = v k + 1 v^* = v_{k+1} v ∗ = v k + 1
实例演示(网格世界)
以含 Forbidden Area 与 Target Area 的网格世界为例:
初始化(k = 0 k=0 k = 0 v 0 = 0 v_0=0 v 0 = 0 q 0 ( s , a ) q_0(s,a) q 0 ( s , a ) v 1 = max a q 0 ( s , a ) v_1 = \max_a q_0(s,a) v 1 = max a q 0 ( s , a )
第一次迭代(k = 1 k=1 k = 1 v 1 v_1 v 1 q 1 ( s , a ) q_1(s,a) q 1 ( s , a ) v 2 v_2 v 2
结论:简单问题 2–3 轮即可收敛;复杂问题需更多迭代,只要终止条件满足即可得到最优解。
编程实现提示
Q 值无需显式存整张表,只需按需计算:q ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ ) q(s,a)= r(s,a)+\gamma \sum_{s'} P(s'\mid s,a) v_k(s') q ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v k ( s ′ )
多个动作并列最优时可随机选一个,不影响收敛。
实践常用:若所有状态 ∣ v k + 1 ( s ) − v k ( s ) ∣ < ϵ |v_{k+1}(s)-v_k(s)|<\epsilon ∣ v k + 1 ( s ) − v k ( s ) ∣ < ϵ
第4课 - 值迭代与策略迭代(策略迭代算法)知识点整理
一、课程定位与算法关联
知识承接 :策略迭代(Policy Iteration)是强化学习中 Model-Based 核心算法,上承贝尔曼方程(策略评估),下接“截断策略迭代”,也是蒙特卡洛方法的基础。与值迭代的关系 :策略迭代与值迭代是“截断策略迭代”的两个端点——策略迭代的“策略评估”迭代至收敛;值迭代只做 1 步评估。差别是对评估精度的取舍。
二、策略迭代算法核心框架
1. 核心循环逻辑
π 0 → 评估 v π 0 → 改进 π 1 → 评估 v π 1 → 改进 π 2 ⋯ ⟶ π ∗ \pi_0 \;\xrightarrow{\text{评估}}\; v^{\pi_0} \;\xrightarrow{\text{改进}}\; \pi_1 \;\xrightarrow{\text{评估}}\; v^{\pi_1} \;\xrightarrow{\text{改进}}\; \pi_2 \; \cdots \;\longrightarrow \pi^* π 0 评估 v π 0 改进 π 1 评估 v π 1 改进 π 2 ⋯ ⟶ π ∗
2. 两大核心步骤
步骤 目标 元素级数学形式 核心操作 策略评估 (PE) 给定 π k \pi_k π k v π k v^{\pi_k} v π k v π k ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) ] v^{\pi_k}(s)=\sum_a \pi_k(a\mid s)\Big[r(s,a)+\gamma\sum_{s'} P(s'\mid s,a)v^{\pi_k}(s')\Big] v π k ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) ] 迭代直到值向量变化 < 阈值 策略改进 (PI) 基于 v π k v^{\pi_k} v π k π k + 1 \pi_{k+1} π k + 1 π k + 1 ( s ) = argmax a [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) ] \pi_{k+1}(s)=\operatorname*{argmax}_a\Big[r(s,a)+\gamma\sum_{s'}P(s'\mid s,a)v^{\pi_k}(s')\Big] π k + 1 ( s ) = argmax a [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) ] 计算所有 q π k ( s , a ) q^{\pi_k}(s,a) q π k ( s , a )
三、关键问题解答
1. 策略评估的两种方法
解析解:矩阵形式 v = ( I − γ P π ) − 1 R π v = (I-\gamma P^{\pi})^{-1} R^{\pi} v = ( I − γ P π ) − 1 R π
迭代解:从 v ( 0 ) v^{(0)} v ( 0 ) v ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v ( j ) ( s ′ ) ] v^{(j+1)}(s)=\sum_a \pi_k(a\mid s)\Big[r(s,a)+\gamma\sum_{s'}P(s'\mid s,a) v^{(j)}(s')\Big] v ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v ( j ) ( s ′ ) ] max s ∣ v ( j + 1 ) ( s ) − v ( j ) ( s ) ∣ < ϵ \max_s |v^{(j+1)}(s)-v^{(j)}(s)|<\epsilon max s ∣ v ( j + 1 ) ( s ) − v ( j ) ( s ) ∣ < ϵ
2. 为什么改进后更优?
策略改进定理:基于 v π k v^{\pi_k} v π k π k + 1 \pi_{k+1} π k + 1 v π k + 1 ( s ) ≥ v π k ( s ) , ∀ s v^{\pi_{k+1}}(s) \ge v^{\pi_k}(s),\;\forall s v π k + 1 ( s ) ≥ v π k ( s ) , ∀ s
[!info]### Lemma 4.1 (Policy improvement)
If π k + 1 = arg max π ( r π + γ P π v π k ) \pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_k}) π k + 1 = arg max π ( r π + γ P π v π k ) v π k + 1 ≥ v π k v_{\pi_{k+1}} \geq v_{\pi_k} v π k + 1 ≥ v π k
Here, v π k + 1 ≥ v π k v_{\pi_{k+1}} \geq v_{\pi_k} v π k + 1 ≥ v π k v π k + 1 ( s ) ≥ v π k ( s ) v_{\pi_{k+1}}(s) \geq v_{\pi_k}(s) v π k + 1 ( s ) ≥ v π k ( s ) s s s
Proof of Lemma 4.1
Since v π k + 1 v_{\pi_{k+1}} v π k + 1 v π k v_{\pi_k} v π k
v π k + 1 = r π k + 1 + γ P π k + 1 v π k + 1 , v_{\pi_{k+1}} = r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}, v π k + 1 = r π k + 1 + γ P π k + 1 v π k + 1 ,
v π k = r π k + γ P π k v π k . v_{\pi_k} = r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}. v π k = r π k + γ P π k v π k .
Since π k + 1 = arg max π ( r π + γ P π v π k ) \pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_k}) π k + 1 = arg max π ( r π + γ P π v π k )
r π k + 1 + γ P π k + 1 v π k ≥ r π k + γ P π k v π k . r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k} \geq r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}. r π k + 1 + γ P π k + 1 v π k ≥ r π k + γ P π k v π k .
It then follows that
v π k − v π k + 1 = ( r π k + γ P π k v π k ) − ( r π k + 1 + γ P π k + 1 v π k + 1 ) ≤ ( r π k + 1 + γ P π k + 1 v π k ) − ( r π k + 1 + γ P π k + 1 v π k + 1 ) ≤ γ P π k + 1 ( v π k − v π k + 1 ) . \begin{align*}
v_{\pi_k} - v_{\pi_{k+1}} &= (r_{\pi_k} + \gamma P_{\pi_k} v_{\pi_k}) - (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) \\
&\leq (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) \\
&\leq \gamma P_{\pi_{k+1}} (v_{\pi_k} - v_{\pi_{k+1}}).
\end{align*} v π k − v π k + 1 = ( r π k + γ P π k v π k ) − ( r π k + 1 + γ P π k + 1 v π k + 1 ) ≤ ( r π k + 1 + γ P π k + 1 v π k ) − ( r π k + 1 + γ P π k + 1 v π k + 1 ) ≤ γ P π k + 1 ( v π k − v π k + 1 ) . Therefore,
v π k − v π k + 1 ≤ γ 2 P π k + 1 2 ( v π k − v π k + 1 ) ≤ ⋯ ≤ γ n P π k + 1 n ( v π k − v π k + 1 ) ≤ lim n → ∞ γ n P π k + 1 n ( v π k − v π k + 1 ) = 0. \begin{align*}
v_{\pi_k} - v_{\pi_{k+1}} &\leq \gamma^2 P_{\pi_{k+1}}^2 (v_{\pi_k} - v_{\pi_{k+1}}) \leq \dots \leq \gamma^n P_{\pi_{k+1}}^n (v_{\pi_k} - v_{\pi_{k+1}}) \\
&\leq \lim_{n \to \infty} \gamma^n P_{\pi_{k+1}}^n (v_{\pi_k} - v_{\pi_{k+1}}) = 0.
\end{align*} v π k − v π k + 1 ≤ γ 2 P π k + 1 2 ( v π k − v π k + 1 ) ≤ ⋯ ≤ γ n P π k + 1 n ( v π k − v π k + 1 ) ≤ n → ∞ lim γ n P π k + 1 n ( v π k − v π k + 1 ) = 0. The limit is due to the facts that γ n → 0 \gamma^n \to 0 γ n → 0 n → ∞ n \to \infty n → ∞ P π k + 1 n P_{\pi_{k+1}}^n P π k + 1 n n n n
3. 收敛性
单调:v π k v^{\pi_k} v π k v ∗ v^* v ∗
折扣:γ ∈ [ 0 , 1 ) \gamma\in[0,1) γ ∈ [ 0 , 1 ) v π k → v ∗ v^{\pi_k} \to v^* v π k → v ∗ π ∗ \pi^* π ∗
[!info]
Theorem 4.1 (Convergence of policy iteration). The state value sequence { v π k } k = 0 ∞ \{v_{\pi_k}\}^\infty_{k=0} { v π k } k = 0 ∞ v ∗ v^∗ v ∗ { π k } k = 0 ∞ \{\pi_k\}_{k=0}^\infty { π k } k = 0 ∞
Proof of Theorem 4.1
The idea of the proof is to show that the policy iteration algorithm converges faster than the value iteration algorithm.
In particular, to prove the convergence of { v π k } k = 0 ∞ \{v_{\pi_k}\}_{k=0}^\infty { v π k } k = 0 ∞ { v k } k = 0 ∞ \{v_k\}_{k=0}^\infty { v k } k = 0 ∞ v k + 1 = f ( v k ) = max π ( r π + γ P π v k ) . v_{k+1} = f(v_k) = \max_\pi (r_\pi + \gamma P_\pi v_k). v k + 1 = f ( v k ) = max π ( r π + γ P π v k ) . v k v_k v k v ∗ v^* v ∗ v 0 v_0 v 0
For k = 0 k=0 k = 0 v 0 v_0 v 0 v π 0 ≥ v 0 v_{\pi_0} \geq v_0 v π 0 ≥ v 0 π 0 \pi_0 π 0
We next show that v k ≤ v π k ≤ v ∗ v_k \leq v_{\pi_k} \leq v^* v k ≤ v π k ≤ v ∗ k k k
For k ≥ 0 k \geq 0 k ≥ 0 v π k ≥ v k v_{\pi_k} \geq v_k v π k ≥ v k
For k + 1 k+1 k + 1
v π k + 1 − v k + 1 = ( r π k + 1 + γ P π k + 1 v π k + 1 ) − max π ( r π + γ P π v k ) ≥ ( r π k + 1 + γ P π k + 1 v π k ) − max π ( r π + γ P π v k ) (because v π k + 1 ≥ v π k by Lemma 4.1 and P π k + 1 ≥ 0 ) = ( r π k + 1 + γ P π k + 1 v π k ) − ( r π k ′ + γ P π k ′ v k ) (suppose π k ′ = arg max π ( r π + γ P π v k ) ) ≥ ( r π k ′ + γ P π k ′ v π k ) − ( r π k ′ + γ P π k ′ v k ) (because π k + 1 = arg max π ( r π + γ P π v π k ) ) = γ P π k ′ ( v π k − v k ) . \begin{align*}
v_{\pi_{k+1}} - v_{k+1} &= (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_{k+1}}) - \max_\pi (r_\pi + \gamma P_\pi v_k) \\
&\geq (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - \max_\pi (r_\pi + \gamma P_\pi v_k) \quad \text{(because $v_{\pi_{k+1}} \geq v_{\pi_k}$ by Lemma 4.1 and $P_{\pi_{k+1}} \geq 0$)} \\
&= (r_{\pi_{k+1}} + \gamma P_{\pi_{k+1}} v_{\pi_k}) - (r_{\pi_k'} + \gamma P_{\pi_k'} v_k) \quad \text{(suppose $\pi_k' = \arg\max_\pi (r_\pi + \gamma P_\pi v_k)$)} \\
&\geq (r_{\pi_k'} + \gamma P_{\pi_k'} v_{\pi_k}) - (r_{\pi_k'} + \gamma P_{\pi_k'} v_k) \quad \text{(because $\pi_{k+1} = \arg\max_\pi (r_\pi + \gamma P_\pi v_{\pi_k})$)} \\
&= \gamma P_{\pi_k'} (v_{\pi_k} - v_k).
\end{align*} v π k + 1 − v k + 1 = ( r π k + 1 + γ P π k + 1 v π k + 1 ) − π max ( r π + γ P π v k ) ≥ ( r π k + 1 + γ P π k + 1 v π k ) − π max ( r π + γ P π v k ) (because v π k + 1 ≥ v π k by Lemma 4.1 and P π k + 1 ≥ 0) = ( r π k + 1 + γ P π k + 1 v π k ) − ( r π k ′ + γ P π k ′ v k ) (suppose π k ′ = arg max π ( r π + γ P π v k ) ) ≥ ( r π k ′ + γ P π k ′ v π k ) − ( r π k ′ + γ P π k ′ v k ) (because π k + 1 = arg max π ( r π + γ P π v π k ) ) = γ P π k ′ ( v π k − v k ) . Since v π k − v k ≥ 0 v_{\pi_k} - v_k \geq 0 v π k − v k ≥ 0 P π k ′ P_{\pi_k'} P π k ′ P π k ′ ( v π k − v k ) ≥ 0 P_{\pi_k'} (v_{\pi_k} - v_k) \geq 0 P π k ′ ( v π k − v k ) ≥ 0 v π k + 1 − v k + 1 ≥ 0 v_{\pi_{k+1}} - v_{k+1} \geq 0 v π k + 1 − v k + 1 ≥ 0
Therefore, we can show by induction that v k ≤ v π k ≤ v ∗ v_k \leq v_{\pi_k} \leq v^* v k ≤ v π k ≤ v ∗ k ≥ 0 k \geq 0 k ≥ 0 v k v_k v k v ∗ v^* v ∗ v π k v_{\pi_k} v π k v ∗ v^* v ∗
四、策略迭代伪代码
初始化:随机策略 π 0 \pi_0 π 0 γ \gamma γ ϵ \epsilon ϵ
循环直到策略稳定:
策略评估:求解Bellman公式,这里使用迭代求 v π k v_{\pi_k} v π k v ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v ( j ) ( s ′ ) ] v^{(j+1)}(s)=\sum_a \pi_k(a\mid s)\Big[r(s,a)+\gamma\sum_{s'}P(s'\mid s,a)v^{(j)}(s')\Big] v ( j + 1 ) ( s ) = ∑ a π k ( a ∣ s ) [ r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v ( j ) ( s ′ ) ] max s ∣ v ( j + 1 ) ( s ) − v ( j ) ( s ) ∣ < ϵ \max_s |v^{(j+1)}(s)-v^{(j)}(s)|<\epsilon max s ∣ v ( j + 1 ) ( s ) − v ( j ) ( s ) ∣ < ϵ v π k = v ( j + 1 ) v_{\pi_k}=v^{(j+1)} v π k = v ( j + 1 )
策略改进:对每个 s s s q π k ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) q_{\pi_k}(s,a)=r(s,a)+\gamma\sum_{s'}P(s'\mid s,a)v_{\pi_k}(s') q π k ( s , a ) = r ( s , a ) + γ ∑ s ′ P ( s ′ ∣ s , a ) v π k ( s ′ ) π k + 1 ( s ) \pi_{k+1}(s) π k + 1 ( s )
若 π k + 1 = π k \pi_{k+1}=\pi_k π k + 1 = π k π k ← π k + 1 \pi_k\leftarrow\pi_{k+1} π k ← π k + 1
输出: π ∗ = π k + 1 , v ∗ = v π k + 1 \pi^*=\pi_{k+1},\; v^*=v_{\pi_{k+1}} π ∗ = π k + 1 , v ∗ = v π k + 1
五、实例
1. 2 格网格
状态:s 1 , s 2 s_1,s_2 s 1 , s 2 s 2 s_2 s 2
动作:左、停、右。
奖励:r ( s 2 , ⋅ ) = 1 r(s_2,\cdot)=1 r ( s 2 , ⋅ ) = 1 − 1 -1 − 1
初始策略 π 0 \pi_0 π 0
评估得:长期陷入 s 1 s_1 s 1 v π 0 ( s 2 ) = 1 v^{\pi_0}(s_2)=1 v π 0 ( s 2 ) = 1
改进:在 s 1 s_1 s 1 π 1 ( s 1 ) = 右 \pi_1(s_1)=\text{右} π 1 ( s 1 ) = 右 π 1 ( s 2 ) = 停 \pi_1(s_2)=\text{停} π 1 ( s 2 ) = 停
2. 5×5 网格(含禁止区)
现象:靠近目标的状态先优化。
原因:这些状态的值先接近最优,使其相邻状态的 q q q
六、实现注意事项
策略评估不必极度精确,可用较宽松 ϵ \epsilon ϵ
多最优动作可随机选或平均分配;最终仍收敛到同一 π ∗ \pi^* π ∗
需准备高效结构存储 P ( s ′ ∣ s , a ) P(s'\mid s,a) P ( s ′ ∣ s , a ) r ( s , a ) r(s,a) r ( s , a ) q ( s , a ) q(s,a) q ( s , a )
第4课-值迭代与策略迭代(截断策略迭代算法)知识点整理
一、核心算法关系框架
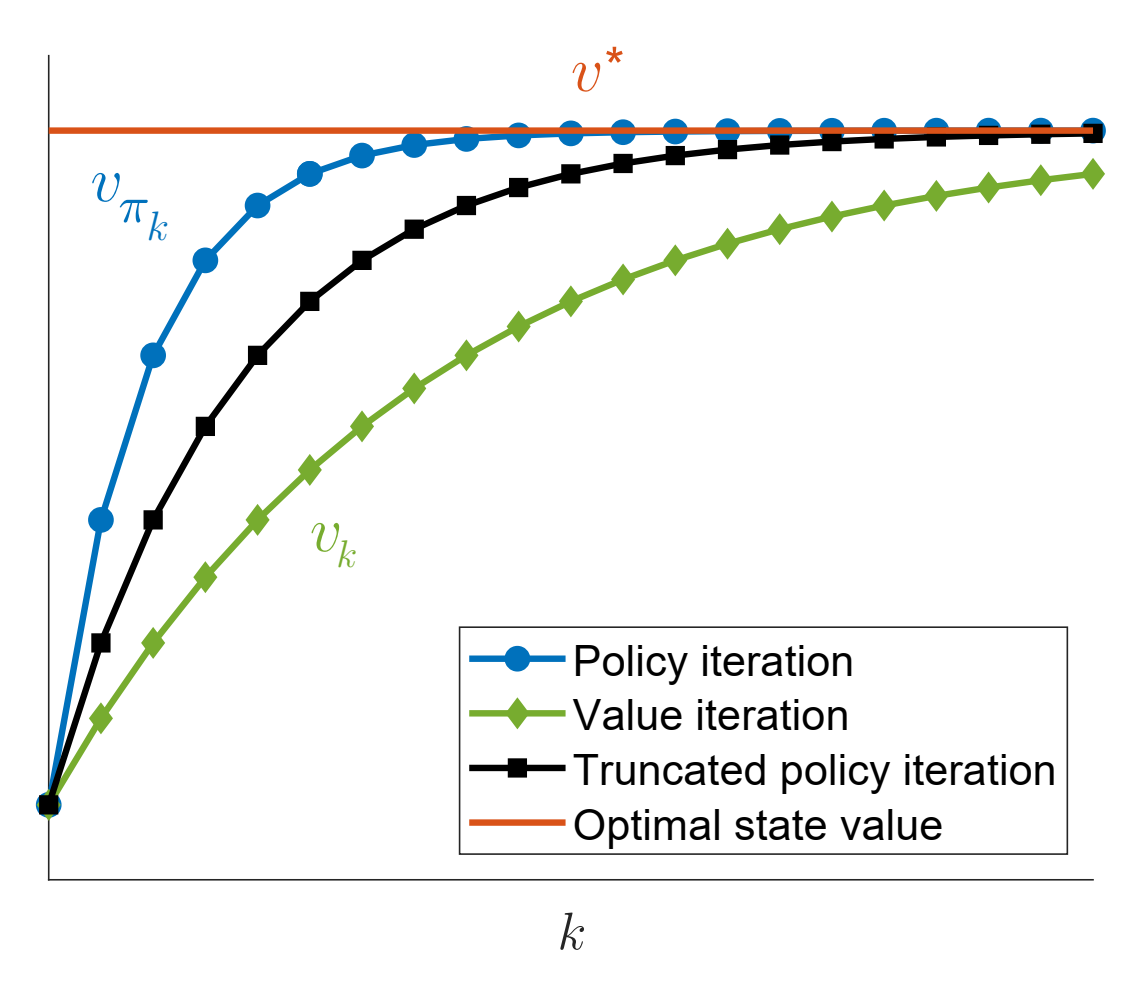
截断策略迭代(Truncated Policy Iteration)并非独立算法,而是值迭代(Value Iteration)与策略迭代(Policy Iteration)的一般化推广 ,后两者是截断策略迭代的“极端特殊情况”:
当截断迭代步数(j)=1时,截断策略迭代退化为值迭代;
当截断迭代步数(j)=∞ \infty ∞
二、三大算法核心流程对比
1. 策略迭代(Policy Iteration)
核心逻辑
从初始策略π 0 \pi_0 π 0 (可任意设定,无需最优)出发,通过“策略评估→策略改进”的循环迭代,逐步逼近最优策略与最优状态值(v ∗ v^* v ∗
关键步骤(第k轮迭代)
策略评估(Policy Evaluation) :针对当前策略π k \pi_k π k v π k v_{\pi_k} v π k 内嵌无穷次迭代 收敛到精确解v π k v_{\pi_k} v π k
数学逻辑:v π k ( s ) = E [ R k + 1 + γ v π k ( S k + 1 ) ∣ S k = s , π k ] v_{\pi_k}(s) = \mathbb{E}[R_{k+1} + \gamma v_{\pi_k}(S_{k+1}) | S_k=s, \pi_k] v π k ( s ) = E [ R k + 1 + γ v π k ( S k + 1 ) ∣ S k = s , π k ]
迭代过程:从任意初始值v π k ( 0 ) v_{\pi_k}(0) v π k ( 0 ) v π k ( j + 1 ) = E [ R k + 1 + γ v π k ( j ) ( S k + 1 ) ∣ S k = s , π k ] v_{\pi_k}(j+1) = \mathbb{E}[R_{k+1} + \gamma v_{\pi_k}(j)(S_{k+1}) | S_k=s, \pi_k] v π k ( j + 1 ) = E [ R k + 1 + γ v π k ( j ) ( S k + 1 ) ∣ S k = s , π k ] v π k ( j ) v_{\pi_k}(j) v π k ( j ) v π k v_{\pi_k} v π k
策略改进(Policy Improvement) :基于得到的v π k v_{\pi_k} v π k π k + 1 \pi_{k+1} π k + 1
数学逻辑:π k + 1 ( s ) = arg max a E [ R k + 1 + γ v π k ( S k + 1 ) ∣ S k = s , A k = a ] \pi_{k+1}(s) = \arg\max_a \mathbb{E}[R_{k+1} + \gamma v_{\pi_k}(S_{k+1}) | S_k=s, A_k=a] π k + 1 ( s ) = arg max a E [ R k + 1 + γ v π k ( S k + 1 ) ∣ S k = s , A k = a ]
特点
理论上需“无穷次内嵌迭代”完成策略评估,精度高但计算成本极高 ;
实际工程中无法实现(无法计算无穷步),需通过截断迭代近似。
2. 值迭代(Value Iteration)
核心逻辑
从初始状态值v 0 v_0 v 0 (可任意设定)出发,通过“策略更新→值更新”的简化循环,直接逼近最优状态值v ∗ v^* v ∗
关键步骤(第k轮迭代)
策略更新(Policy Update) :基于当前状态值v k v_k v k π k + 1 \pi_{k+1} π k + 1
数学逻辑:π k + 1 ( s ) = arg max a E [ R k + 1 + γ v k ( S k + 1 ) ∣ S k = s , A k = a ] \pi_{k+1}(s) = \arg\max_a \mathbb{E}[R_{k+1} + \gamma v_k(S_{k+1}) | S_k=s, A_k=a] π k + 1 ( s ) = arg max a E [ R k + 1 + γ v k ( S k + 1 ) ∣ S k = s , A k = a ]
值更新(Value Update) :仅通过1步迭代 更新状态值v k + 1 v_{k+1} v k + 1 v π k + 1 v_{\pi_{k+1}} v π k + 1
数学逻辑:v k + 1 ( s ) = E [ R k + 1 + γ v k ( S k + 1 ) ∣ S k = s , π k + 1 ] v_{k+1}(s) = \mathbb{E}[R_{k+1} + \gamma v_k(S_{k+1}) | S_k=s, \pi_{k+1}] v k + 1 ( s ) = E [ R k + 1 + γ v k ( S k + 1 ) ∣ S k = s , π k + 1 ]
特点
策略评估仅1步,计算成本低但单轮精度较低 ;
无需显式维护策略,通过值迭代直接逼近v ∗ v^* v ∗ v ∗ v^* v ∗
3. 截断策略迭代(Truncated Policy Iteration)
核心逻辑
解决前两种算法的极端性:在策略评估阶段引入有限截断步数j (可自定义,如j=2、10、100),平衡精度与计算成本。
关键步骤(第k轮迭代)
策略评估(截断版) :针对当前策略π k \pi_k π k v k − 1 v_{k-1} v k − 1 j步内嵌迭代 ,得到近似状态值v π k ( j ) v_{\pi_k}(j) v π k ( j ) v π k v_{\pi_k} v π k 策略改进 :基于近似值v π k ( j ) v_{\pi_k}(j) v π k ( j ) π k + 1 \pi_{k+1} π k + 1 迭代终止 :当截断步数j达到预设阈值时,停止当前轮策略评估,进入下一轮循环。
伪代码核心差异
与策略迭代伪代码结构一致,仅将“策略评估的收敛判断”替换为“截断步数计数判断”:
策略迭代:while v π k ( j ) v_{\pi_k}(j) v π k ( j )
截断策略迭代:for j in 1 to 预设步数 → 执行j步后停止。
三、三大算法关键差异与核心结论
1. 核心差异:策略评估的迭代步数
算法 策略评估迭代步数 状态值精度 计算成本 工程实用性 策略迭代 ∞ \infty ∞ 最高(精确v π k v_{\pi_k} v π k 极高(不可实现) 仅理论参考 值迭代 1 较低(近似v π k + 1 v_{\pi_{k+1}} v π k + 1 极低 适合快速迭代场景 截断策略迭代 自定义j(有限) 中等(v π k ( j ) v_{\pi_k}(j) v π k ( j ) 中等(可控) 实际工程首选
2. 收敛性保障