(Vanilla) Recurrent Neural Network
ht=fw(ht−1,xt) —> ht=tanh(Whhht−1+Wxhxt)yt=Whyht
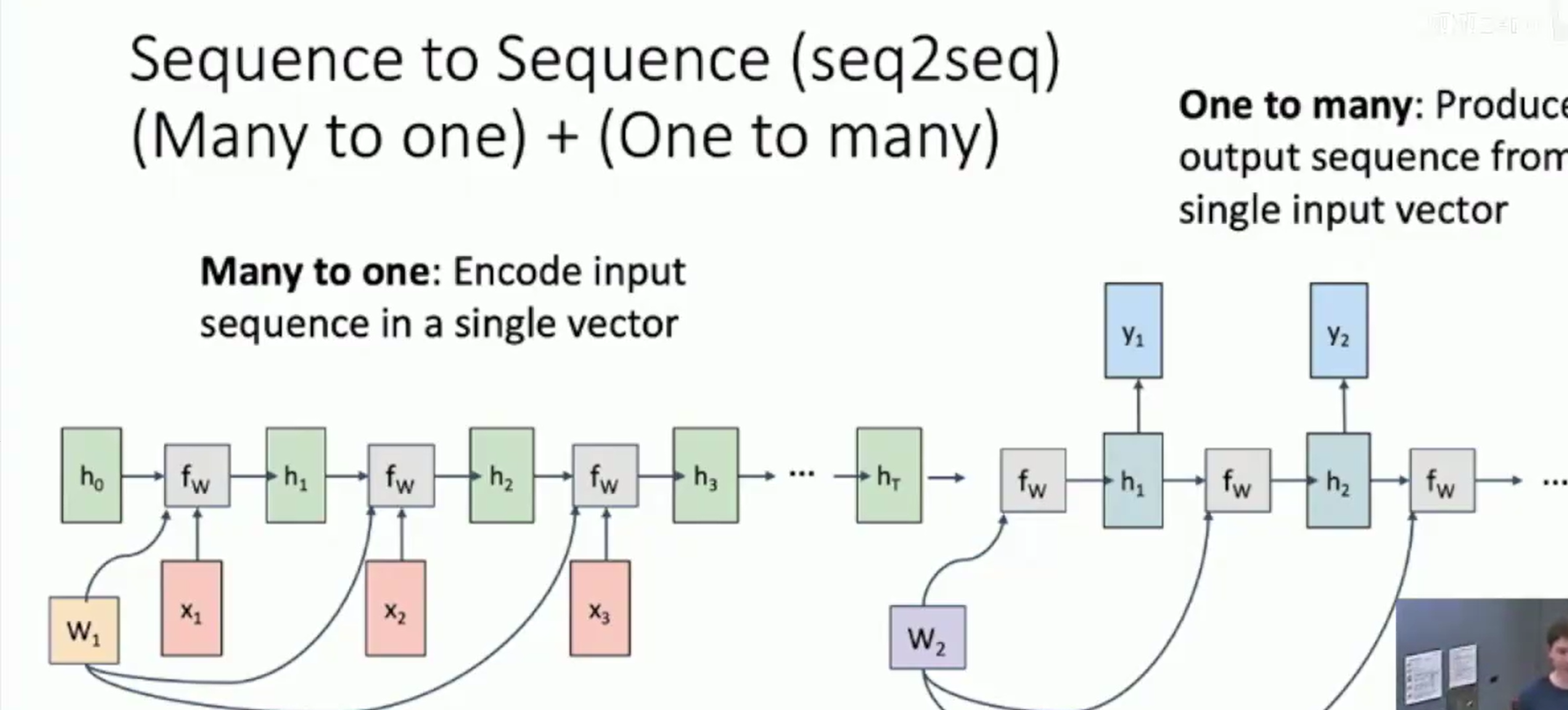
Sequence 2 Sequence :
Many2One : Encode input sequence in a single vector
One2Many: Produce output sequence from single input vector
Truncated Backpropagation Thru Time: Chunk the data and backprop in the every small chunk . They will remember the hidden weights.
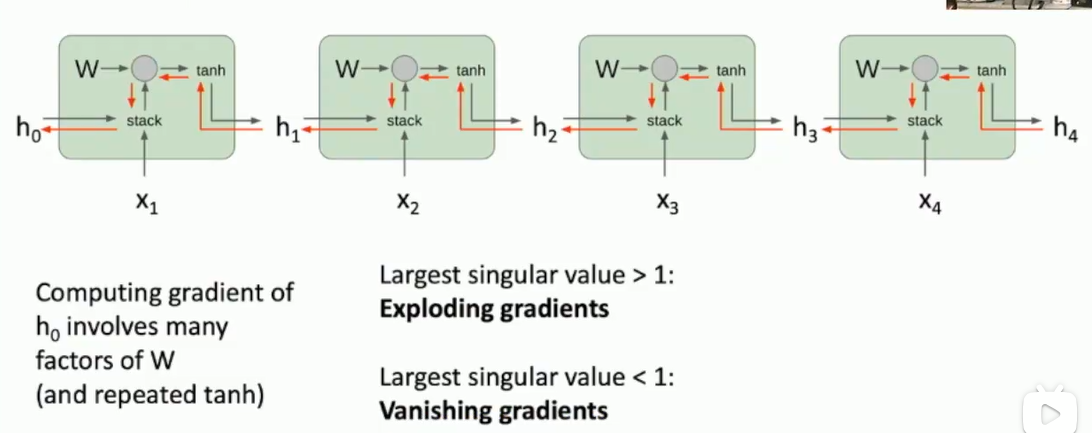
Vanilla RNN Gradient Flow
LSTM: σ stands for sigmoid function
ifogctht=σσσtanhW(xtht−1)=f⊙ct−1+i⊙g=o⊙tanh(ct)
input gate: whether to write the cell
forget gate: whether to erase the cell
output gate: how much to reveal cell
gate gate: how much to write to cell